

Christian Wied
IBM
Industrie 4.0
Edge Computing mit Machine Learning
Wie neue „Ready-to-Go“-Cloud-Box-Lösungen es Unternehmen ermöglichen, die Herrschaft über ihre Daten wieder zurückzubekommen, indem sie mit Hilfe von Machine-Learning-Algorithmen direkt an der Produktionsstraße (im Edge Device) ausgewertet werden – Entscheidung über die Weiterleitung inklusive.
Produktionsumgebungen wie Fertigungsstraßen liefern mit zahlreichen Maschinen und integrierten Sensoren täglich Massen an Daten, die sich für viel mehr eignen als die bloße Steuerung des aktuellen Produktionsprozesses. Viele dieser Daten werden aufgrund fehlender oder nicht vollständiger Datenmodelle noch gar nicht aktiv ausgewertet. Um vorbereitet zu sein und um keine Daten zu verlieren, werden eher zu viele Daten gespeichert. Data Lakes sind eine Teillösung hierfür, aber auch mit Kosten verbunden.
Bei Gesprächen mit Datenanalysten kam heraus, dass sie nicht immer alle Daten, die sie benötigen, auch bekommen. Das liegt unter anderem an den wachsenden Datenmengen und der damit verbundenen steigenden Auslastung der Netzwerke.
Das haben bereits zahlreiche Industrieunternehmen erkannt. Sie möchten diese Daten in Echtzeit auswerten. Public-Cloud-Lösungen boten sich anfangs als die optimale, schnelle Lösung an. Man schickt einfach alle Daten zur Datenauswertung in die Cloud. Je nach Anwendungsfall und Datenmenge funktioniert dieser Weg recht gut. Viele Unternehmen stellen jedoch vermehrt fest, dass weitere Anwendungsfälle mit wachsenden Datenmengen im Hinblick auf Datensicherheit, Latenzzeit und Echtzeitverarbeitung eine kombinierte edge-/cloud-basierende Infrastruktur benötigen.
Am Boden bleiben
Die Lösung ist so einfach wie genial: „Analytische Datenreduzierung und Auswertung (ADA)“ direkt an der Fertigungsstraße in einem auf Standards basierenden Edge Device, ohne auf alle Vorzüge einer Cloud-Umgebung verzichten zu müssen. Was bedeutet das? Das Unternehmen wertet die Daten direkt am Entstehungsort aus und entscheidet direkt vor Ort, wohin die Daten geschickt werden sollen. Dies kann mit Hilfe eines Machine-Learning-Algorithmus oder auch eigenen container-basierenden Anwendungen erfolgen.
Neue Ready-to-Go-Lösungen können im Zusammenspiel mit modernen Containertechnologien genau dies leisten und noch mehr – die Anwender gewinnen wieder mehr Kontrolle über ihre Daten, Datenmengen werden reduziert und die Sicherheit wird erhöht.

Wenn die Anzahl der vernetzten Fertigungsmaschinen steigt, wird eine „Analytische Datenreduzierung und Auswertung (ADA)“ direkt an der Fertigungsstraße zunehmend sinnvoller. Fotos: IBM

Mit modernen „Ready to Go“-Cloud-Box-Systemen als ADA-Lösung direkt am Edge Gerät können Unternehmen wieder allein entscheiden, was mit ihren Daten passieren soll.

IBM hat mit der „Cloud-in-a-Box“-ADA-EC-Lösung eine solche Ready-to-Go-Cloud-Lösung präsentiert, wie hier erstmalig im Mai 2019 auf der Think at IBM in Berlin

Das Angebot beinhaltet zusätzlich eine Materna Managed-Services-Option für die Container-Infrastruktur und läuft auf standardisierten Industrie-PCs von Spectra.
Nachdem das Machine-Learning-Modell auf Basis von aktuellen Produktionsdaten erstellt worden ist, nimmt es die Arbeit direkt an der Edge auf. In Verbindung mit modernen Integration-Bus- Technologien werden nur noch die relevanten Daten an die zentrale Datenanalyse-Plattform, wo auch immer diese steht, weitergeleitet und dort mit anderen Unternehmensdaten gemeinsam ausgewertet. Wenn gewünscht, können die nicht verwendeten Rohdaten oder Teile davon dezentral gespeichert oder gepuffert werden.
Neben der stark reduzierten Datenmenge ist diese Architektur zusätzlich noch ein großer Sicherheitsgewinn, denn sicherheitsrelevante Daten können schon am Entstehungsort verschlüsselt, entsprechend weitergeleitet oder auch gelöscht werden.
Aktuelle, auf Containertechnologie basierende ADA-Lösungen sind per Design hoch flexibel und können je nach Bedarf angepasst werden. Dabei spielen Anzahl, Größe oder Ort der Cloud-Instanzen keine Rolle, ein zentrales Management ist fast immer möglich. Dies funktioniert auch bei einer Kombination aus einer oder mehreren Public- oder Private-Cloud-Umgebungen der gängigen Anbieter, aber auch in einer eigenen, privaten Unternehmens-Cloud.
Die Planung entscheidet
Wie bei allem ist die Planung sehr wichtig. Werden bestimmte Regeln bei der Entwicklung der Lösungen beherzigt, die später in Docker-Containern laufen sollen, sind der Flexibilität fast keine Grenzen mehr gesetzt. Die Container laufen auf fast allen aktuellen Cloud-Infrastrukturen (On-Prem, Off-Prem, Public oder Private). Lösungen von verschiedenen Firmen aus dem Bereich Multi-Cloud-Management, Cloud Automation und Monitoring runden das Bild solch einer Multi-Cloud-Umgebung als einfach und effizient zu managen ab. Hierbei werden die Edge-Komponenten, basierend auf Standard-Cloud-Technologien, mit eingebunden.
Aller Anfang ist schwer
Auch wenn das Bewusstsein für die Bedeutung von Produktionsprozessdaten groß ist, scheuten viele Unternehmen den Schritt, die Daten für weitere Auswertungen zu nutzen. Ein Grund dafür ist fehlendes Know-how rund um das Containermanagement.
Solche Infrastrukturen selbst aus einzelnen Open-Source-Komponenten zu erstellen, zu verteilen und zu betreiben, kann in einer überschaubaren Umgebung noch funktionieren. Bei einer größeren Anzahl von Anwendungen, Edge-Systemen und IoT-Devices, wird dies schnell zur Mammutaufgabe.
Sofort einsatzbereit
Wie klein kann eine sichere, voll funktionsfähige Cloud sein? Sehr klein! Und warum ist das wichtig? Dies ist die Basis, um mehr Rechenleistung direkt an die Maschinen beziehungsweise in den Shopfloor zu bringen. Die aktuellen, sofort einsatzbereiten Cloud-in-a-Box-Lösungen bringen eine voll funktionsfähige Cloud mit der notwendigen Rechenleistung ans Endgerät und ermöglichen so die Ausführung von Machine-Learning-Modellen vor Ort.
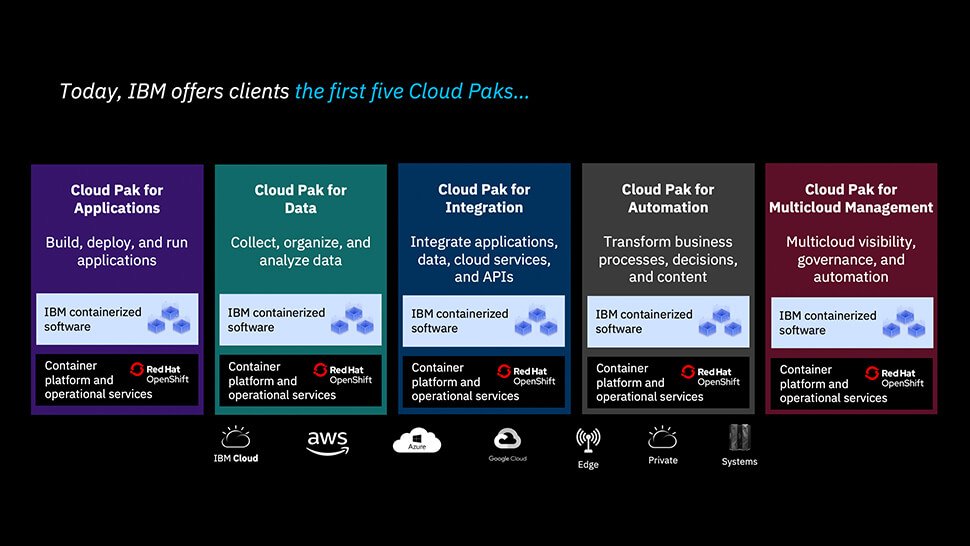
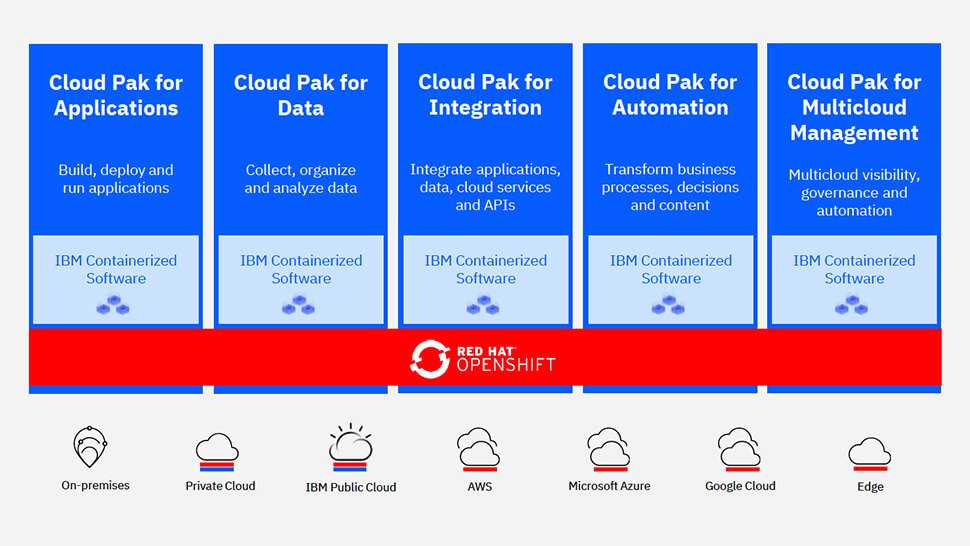
Alle Cloud-Lösungen von IBM basieren auf Red Hat Openshift, sind auf allen gängigen Cloud-Umgebungen lauffähig und zentral verwaltbar. Bilder: IBM
Anwender haben die Möglichkeit, mit den Daten aus ihren Anlagen eigene Machine-Learning-Modelle zu entwickeln, zu trainieren und sie anschließend in Containern über den zentralen unternehmenseigenen App Shop überall dort bereitzustellen, wo sie gebraucht werden.
Die Ergebnisse fließen direkt in die Anpassung und Weiterentwicklung der Modelle, was zu einem Kreislauf führt, der diese Modelle immer weiter verbessert und optimiert. Diese standardisierten Cloud-Boxen wurden speziell für den Einstieg in die Ära KI-gestützter Fertigungslösungen entwickelt. Somit wird es den Unternehmen ermöglicht, ihr Ökosystem intelligent im Kerngeschäft zu erweitern und auszubauen.
Am Rande der Cloud
Mit den aktuell am Markt erhältlichen Lösungen können eigene KI-Anwendungen entwickelt und in die Laufzeitumgebung wie IoT-Endgerät oder Cloud-Box verteilt werden. Die Integration unterschiedlichster Datenquellen, die Datenanalyse wird hierbei sowohl on Premise als auch in der Cloud sichergestellt. Die Software wird vorkonfiguriert geliefert und in die vorhandene Umgebung eingebunden. Unternehmen können damit auf ihre verteilten Daten im Unternehmen zugreifen, diese physisch oder virtuell sammeln, organisieren und analysieren. Mit den damit zur Verfügung stehenden KI-Services ist dies die Basis für eigene KI-Anwendungen.
Fazit
Der Anwendungsfokus in Bezug auf Datenverarbeitung und -analyse in der Produktion wandert von der Cloud hin zum Werks- oder Edge-Level. Der Shopfloor selbst wird ab sofort zum neuen Datenzentrum, was das IT-Netzwerk wesentlich entlasten wird. In den nächsten zwei bis drei Jahren werden diese Datenmengen so stark ansteigen, dass selbst aktuell geplante 5G-Netze nur punktuell helfen können. Nicht jedes Unternehmen wird sich anfangs eine eigene 5G-Infrastruktur in allen Niederlassungen weltweit leisten können und wollen. Daher wird ADA-Edge Computing eine immer größere Rolle spielen, denn allein durch die ständig wachsende Zahl der angeschlossenen Geräte wird es für das Netzwerk unumgänglich sein, die Daten unmittelbar am Entstehungsort zu verarbeiten.
Damit Unternehmen frühzeitig umstellen können und von den Möglichkeiten moderner Software-Virtualisierung und Machine-Learning-Modellen profitieren können, wurden schnell implementierbare Lösungen „Ready to go“ entwickelt, die alle Grundfunktionen für ein einfaches Multi-Cloud-Management sowie die Entwicklung und Anwendung von Machine-Learning-Verfahren am Rande der Cloud mitbringen.
Kontakt
Christian Wied
IBM Account Manager Cloud Software – Industrial Clients
IBM Deutschland GmbH
München
Tel. +49 8104 6476 53
E-Mail senden
Ralf Schoppenhauer
IBM Senior IT Architect – Hybrid Cloud, Internet of Systems, Machine Learning
Hannover
Tel. +49 171 5529 276
E-Mail senden